LD-SODA: Learning-based Data Analysis
Statistics, Optimization, Dynamics and Approximation
funded by "Landesforschungsförderung Hamburg, Hamburger Behörde für Wissenschaft, Forschung und Gleichstellung (BWFG)"
Principal Investigators of this Collaborative Research Project
- Prof. Dr. Sarah Hallerberg (Spokesperson): Hamburg University of Applied Sciences, Faculty of Engineering and Computer Science, Department of Mechanical Engineering and Production Management
- Prof. Dr. Armin Iske: University of Hamburg, Department of Mathematics
- Prof. Dr. Ivo Nowak: Hamburg University of Applied Sciences, Faculty of Engineering and Computer Science, Department of Mechanical Engineering and Production Management
- Jun.-Prof. Dr. Mathias Trabs: University of Hamburg, Department of Mathematics
Project TP-O: New Column-Generation Algorithms for Deep Learning
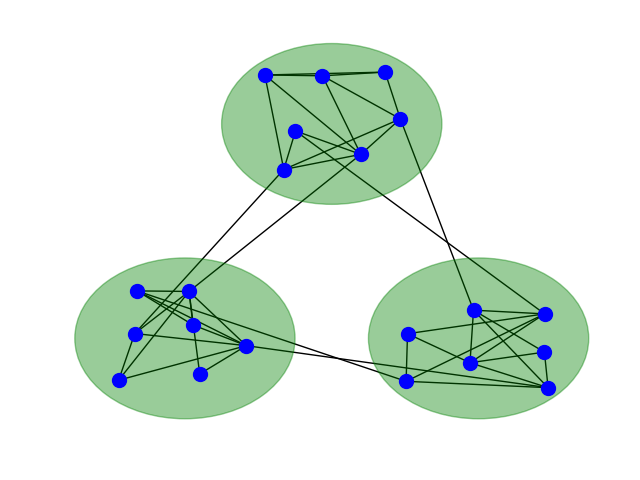
Photo: A. Iske
High-dimensional large data sets from applications require large artificial neural networks. Learning with such networks can be difficult, as the optimization problems required for this are large, nonconvex and nonsmooth. On the other hand, it is often not clear, which network architecture, in particular the number of network layers and components, is the most efficient as this depends on the training data. Too many layers can lead to overfitting and too few layers can deteriorate the approximation quality.
In this project we develop new column generation algorithms for simultaneous determination of optimal parameters and architectures of artificial neural networks. Column generation methods have the advantage, that a master problem defined by inner points is generated. This forms the basis for determining a global and robust solution, as well as for the adaptive growth of neural networks and the distribution of weights in network components, such as in modular mixture-of-experts architectures (see figure).
Project lead: Prof. Dr. Ivo Nowak
Project TP-A: Kernel-based approximation methods for adaptive data analysis
High performance machine learning methods require efficient algorithms for adaptive data analysis, in particular for very large data sets. In relevant applications, however, training data (of growing sizes) are not only very large, but critical in many different ways, e.g., high-dimensional, scattered, incomplete, or uncertain. A reliable analysis of such critical data requires customized and flexible methods from multivariate approximation. To this end, suitable approximation methods were just recently combined with geometrical projection methods of nonlinear dimensionality reduction (NDR).
In this project, we develop and analyze novel concepts of kernel-based approximation schemes for adaptive data analysis. To this end, we construct non-standard kernel functions, from which we obtain flexible and reliable tools for the analysis of critical data. Moreover, we develop adaptive approximation algorithms of sparse representations of large data sets. In the numerical analysis of the resulting approximation algorithms, particular emphasis is placed on their computational complexity, their accuracy and their numerical stability. The combination between kernel-based approximation and nonlinear dimensionality reduction schemes requires suitable characterizations of topplogical and geometrical invariants, in particular for the purpose of data classification. We finally develop nonlinear projection methods, which are invariant under the identified topological and geometrical properties.
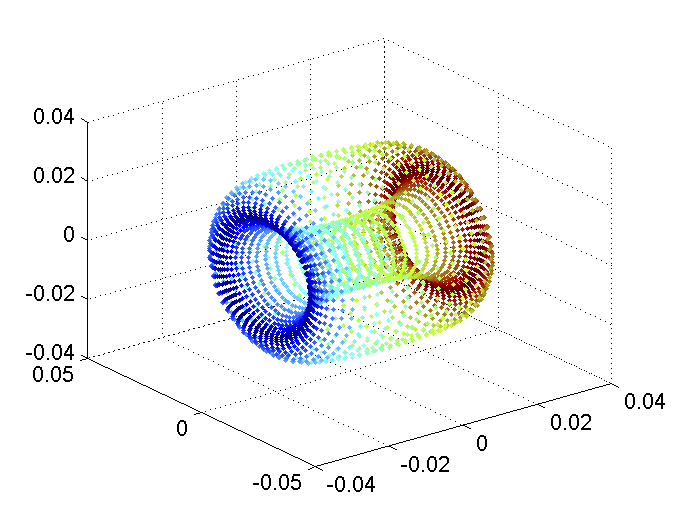
Photo: A. Iske
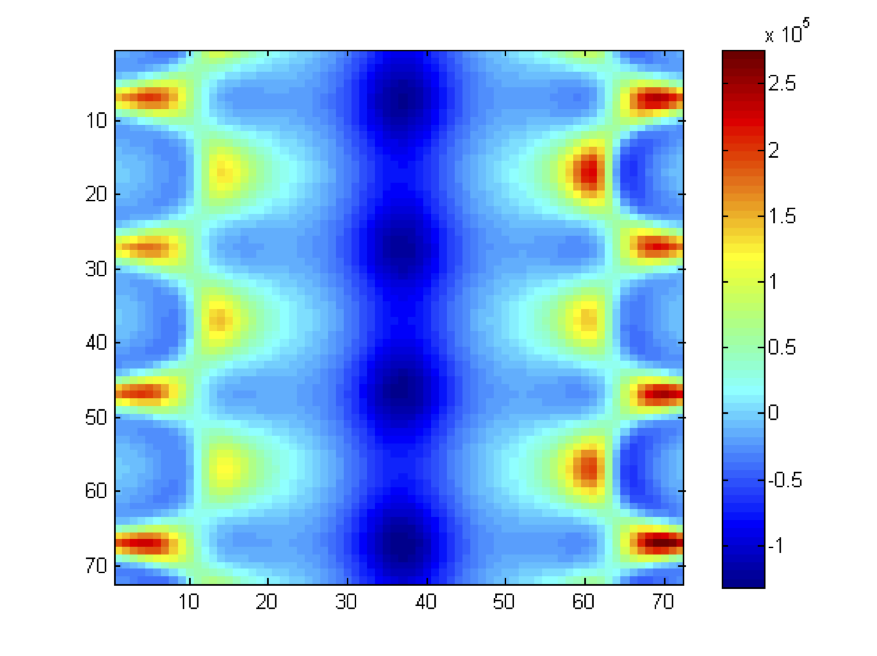
Photo: A. Iske
Project lead: Prof. Dr. Armin Iske